
先日の10月1日に東京証券取引所でトラブルがありましたね。
運用の事例としては、いい機会なので解説したいと思います。
10月7日時点で東京証券取引所から発表されている内容から私の推測も含めてご説明します。

・どんな影響があったの?
・原因は?
・今後の対策は?
こういった疑問に答えます。
ポイント
✔︎本記事の内容
1.東京証券取引所のトラブルをまとめました
2.なんでトラブルが起こったのか?
3.今後の対策について
この記事を書いている僕は、24年間のシステムエンジニア経験のうち、運用中心に経験しています。
こういった僕が解説していきます。
1.東京証券取引所のトラブルをまとめました
まずは、事象から。東京証券取引所の資料から抜粋しています。
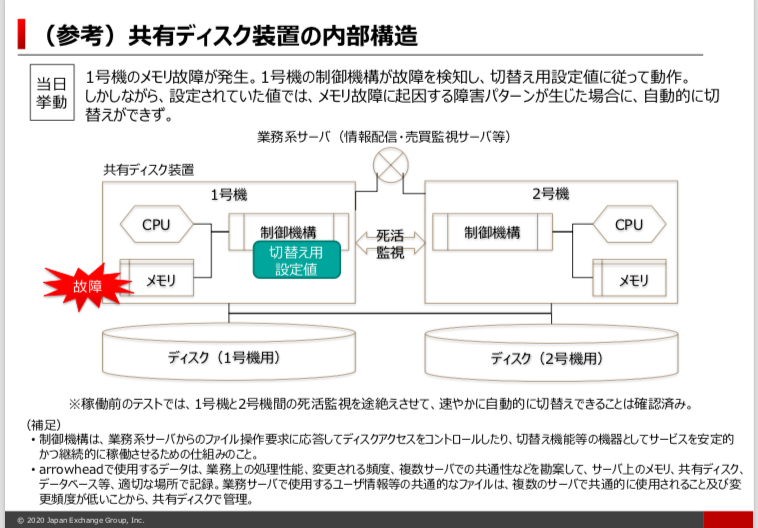
10月1日(木)7:04に株式売買システムで利用している共有ディスク装置1号機のメモリ故障を検知した。
本来であれば、自動で共有ディスク装置2号機に切り替わるところ、切り替わらなかったため、相場情報配信業務、売買監視業務に異常が発生した。
その結果、相場情報が配信できないため、証券会社からの注文経路及び相場配信するネットワークに対して、開始前に遮断処理を実施し、売買を停止した。
共有ディスク装置2号機に自動で切り替わらない場合は、手動で強制的に共有ディスク装置2号機に切り替えることは可能だったが、システム再起動を行った場合、投資家や市場参加者に対して混乱を生じることが想定され、内外の市場参加者とも協議して、終日売買停止することとした。
2日の市場再開に向けて、ハード交換、システム再起動を実施し、万一故障発生時にも速やかに切り替えできる体制を確立する。
今回は1日の売買停止に伴い、3兆円もの損失を出したと言われています。
2.なんでトラブルが起こったのか?
10月7日時点で東証の発表資料から根本原因を推測します。
このような時に、運用エンジニアは、「なぜなぜ分析」という手法を使います。
なぜ?なぜ?と自問自答することで、根本原因を抽出させる必要があるからです。
今回の故障した機器構成の図面です。
原因1:共有ディスクのメモリ故障
最初に発表されている共有ディスクのメモリ故障から考えます。
メモリは、プログラムやデータを一時的に記憶する半導体素子で、メモリに障害が発生するとシステムダウンする場合もあるので、各メーカーもメモリの信頼性を確保しています。
ただ、半導体製品なので、原材料に含まれる微量放射性元素や宇宙船などの影響により、記憶されたビットが反転するエラーは起こり得ます。
そこで、メモリの信頼性を高めるためのデータをチェックする機能を備えています。
また、メモリの物理的な故障に備えるため、スペアメモリやミラーリングという機能を備えている機器もあります。
つまり、ある程度部品が故障することは想定内で設計します。
従って、共有ディスクのメモリ故障は、想定内でシステムを構築しているので、これはトラブルが発生する最初の「きっかけ」に過ぎません。
今回の大きなトラブルが発生した根本原因ではありません。
ちなみに今回はメモリのハード故障と発表されていますので、本来であれば、メモリに故障が起きても、対応できる仕組みが備わっていれば問題は発生しなかった可能性はあります。そこは富士通の調査結果を待ちましょう。
原因2:なぜ切り替わらなかったのか?
次に本来、自動で共有ディスク装置2号機に切り替わるはずなのに、なぜ切り替わらなかったのか?
ここを考えます。
まず、共有ディスク装置内部に制御機構があるので、その制御機構が1号機、2号機双方で死活監視(生きているか死んでいるか呼びかけしている状況のこと)しています。また、自分の部品(CPU、メモリ、ディスク等)の状態も監視しています。
1つのポイントとしては、制御機構がメモリ故障を検知したのか?していないのか?というのがポイントですが、今回、共有ディスク1号機内の制御機構がメモリ故障を検知したようです。
ただ、制御機構の設定の不備で自動的に2号機に切り替わらなかったようです。
どんな不備かと言うと、1号機のメモリが故障しても自動的に2号機に切り替える設定になっていなかったからです。
もう少し深掘りします。
原因3:なぜメモリが故障した場合に自動で切り替える設定になっていなかったのか?
可能性の1つとしては、そもそもメモリ故障を想定していなかったケースです。
その場合は、2号機も同様に自動で切り替える設定をしていないはずです。
もう1つの可能性としては、メモリ故障を想定していたけれども、何らかの理由により1号機だけ設定をしていなかったケースです。
その場合は、2号機は自動で切り替える設定をしています。
その場合の考えられる原因としては、1号機だけ設定ミスをしたか、設定を忘れたか、くらいでしょうか。
いずれにせよ、前者のメモリ故障を想定しないケースも、後者の1号機だけ設定しなかったも、人為的ミスになります。
原因4:なぜ、事前に気づかなかったのか?
更に深掘りします。
1号機の制御機構の設定に問題があったのは事実ですが、なぜその事実を事前に気づかなかったのか?
本来、本番で動く前に試験をします。
それはプログラム試験だったり、新しいディスクを動かす試験だったり、何でも試験を行います。
果たして試験をしたのに気づかなかったのでしょうか。
それとも、試験で見落としていたのでしょうか?
私が思うに、1つの可能性としては、試験をしていなかった可能性があります。
本番機の稼働前にテストをすることになるのですが、テストは発注元の株式会社日本取引所グループの責任の下実施することが多いと思います。つまり、株式会社日本取引所グループが運用テストをOKにしなければ、納品完了にならないのです。
そこで、稼働前の運用テストで、今回のような共有ディスクのメモリ故障時に自動で切り替わるテストをするのか?
という疑問が湧きます。
おそらく、そこまでテストをしていなかったのだろうと推測します。
考えられる理由は2つあります。
・時間がないから
1つ1つの部品故障時に自動で切り替わるかテストをしていたら時間がいくらあっても足りないからです。おそらく、メモリ以外にも部品はあるので部品点数だけでも、かなりの数になると思います。それぞれを部品故障させて、切り替わるテストをすることは現実的ではないと思います。
・擬似的に部品故障を起こすことは技術的に難しいから
株式会社日本取引所グループが意図的に部品故障を起こさせることは、専門知識が必要なので技術的に難しいからです。
・購入した側の責任範囲外と考えられるから
購入した製品の部品故障時に自動で切り替える設定の部分は、顧客側(株式会社日本取引所グループ)としても、そこは「富士通さんやってよ」と言いたいところです。富士通製品であれば尚更です。ただ、厄介なのは、海外製品のディスクを使っている場合です。海外製品は、結構ブラックボックスと言って、開示していないケースもあるので富士通さんも把握することが難しいと思います。また、海外製品なら、尚更意図的に故障させることは難しいでしょう。そこは顧客側(株式会社日本取引所グループ)の権限外と考えると思います。
それでは、どこまで稼働前テストを実施するのでしょうか。
実際に東証の発表資料でも、稼働前のテストでは1号機と2号機間の死活監視を止めて、自動切り替えできていることは確認しています。
稼働前のテストで出来ることは、大抵そのくらいです。
稼働前テストで全てのテストを網羅することは出来ませんので、ある程度割り切りで進めることが一般的です。
従って、原因4のなぜ、事前に気づかなかったのか?の回答としては、テストをしていなかったから(テストが出来なかった事情があったから)
と推測できるのではないでしょうか。
3.今後の対策について
下記対策を同時並行して実施することが挙げられます。
(1)他の設定で漏れがないか机上で確認すること
(2)もし、自動で切り替わらない事象が発生した場合に、人間が対応できるように手順化しておくこと
(1)他の設定で漏れがないか机上で確認すること
まずはすぐに対応できることから始めます。他の装置で同様の設定漏れがないか確認することはした方がいいと思います。
(2)もし、自動で切り替わらない事象が発生した場合に、人間が対応できるように手順化しておくこと
現時点では、既に動いている機器をテストで全てを確認することは難しいので、自動で切り替わらない事象が発生した場合に、「運用対処」するのが現実的になろうかと思います。
つまり、人間が対応することです。
今回のように、自動で切り替わらない事象が発生した場合に、人の手で速やかに強制的に切り替える対応をすることです。
実際には、システム運用者が大抵、24時間365日現場に張り付いています。
東証の発表だと、当日の9時過ぎには、人の手により2号機に切り替えは完了していたのですが、他システムの再起動を伴うため、既に受け付けたデータが消えるなどのリスクを考慮し、当日は取引を停止しています。
ここも検証が必要です。
他システムの再起動しても、データを失うことはないようにすべきです。おそらく手順はあると思います。
最後になりますが、私の経験でも、自動切り替えの仕組みはありますが、自動切り替えできないことは多々ありました。
従って、システムを過信せず、何かあった場合に事前準備することが重要だと多います。
運用というのは、トラブルがなかったら、日の目を見ない少し損な役割かもしれません。だから、経営者から見ると、とかくコスト削減の対象になりやすいです。
でも、今回の問題のように、トラブルが起きたら甚大な影響があります。
今回は1日の売買停止に伴い、3兆円もの損失と言われています。
とてつもない影響です。
そして運用エンジニアは、そのような緊張の中で作業をするので疲弊します。私自身も経験していますが、トラブルが発生するとリーダークラスの人達は2、3日泊まり込みで対応することもありました。ぜひ、運用エンジニアの待遇を改善していただきたいと思います。
{kind=link}